Software developers and architects would instinctively avoid cyclic dependencies given the choice – we’d never consciously create an architecture which was a ball of mud. For instance we’d be more inclined to aim for something like this …
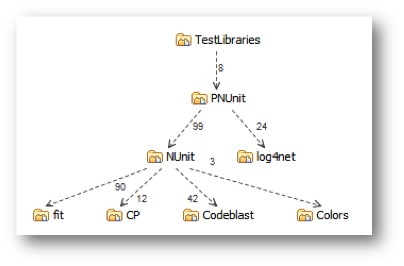
rather than something like this (same components but with cyclic dependencies) …
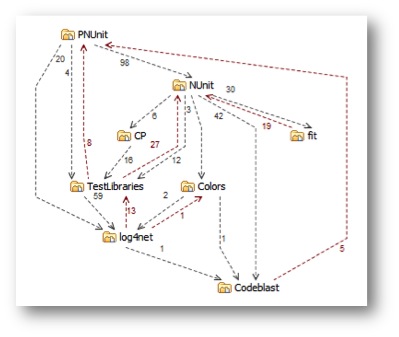
Why? Well the second system has about 2x the number of dependencies. But it seems more than twice as complex. I could create an acyclic model with the same number of dependencies as the second, and we would probably be happy enough with it. There’s something about the cycles themselves.
One thing is for sure – cycles make it much harder to tell the story of a codebase. For the first system I can quite easily explain how PNUnit uses NUnit, which does this, and uses Codeblast for that, and Colors for something else, and so forth. I can’t describe the second system in the same way. I can try to explain that PNUnit uses NUnit, which uses CP, which uses TestLibraries, which uses NUnit (again) and PNUnit (which as already mentioned uses NUnit) and Log4net which uses Testlibraries which uses Log4net (again) which … zzzz … Explainability is clearly related to the number of paths through a system’s dependency graph, and cycles lead to much more paths, and very convoluted explanations! And not just explanations – tangled dependencies clobber any hope of separate testing, reuse, release, and such. This is because tangles explode the overall connectedness or coupling of your codebase, which sends complexity through the roof.
This can be measured.
Cumulative Component Dependency (CCD)
In Large-Scale C++ Software Design, John Lakos talks about dependency (and thereby complexity) being cumulative. His Cumulative Component Dependency, or CCD, recognizes that when one item depends on a second, it really depends on all the items that the second item depends upon, and that they depend upon, repeat. For instance an item can be impacted when anything in its dependency closure changes. The CCD of a system is the sum of the dependencies of every item in the system. It is a very good indicator of the relative complexity of systems. Here’s how it works.

In this simple example with N = 7 items (copied from John’s book), the items on the bottom row are considered to be dependent only on themselves; the items on the second row are each dependent on themselves plus 2 items on the bottom row; the top item is dependent on itself plus the 2 sets of 3; CCD is the sum of all the numbers, so for this system it is 17.
The overall number of items and dependencies impacts the CCD somewhat, but when dependencies form cycles, the effect on CCD is explosive.
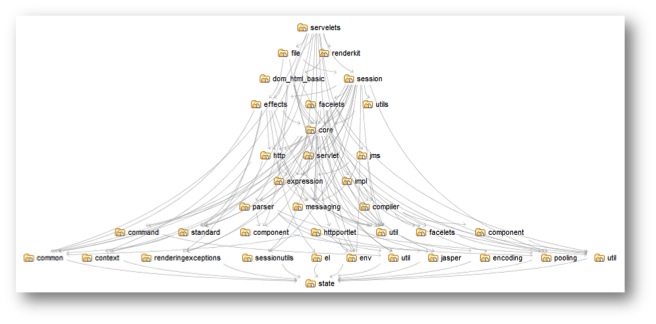
For example the dependencies for this set of items all point downward (and are therefor acyclic), and its CCD is something less than 164 (it would be 164 if every item depended on every item on the next row down, which isn’t the case). By adding a single dependency from the item on the bottom layer to the item at the top, we create cycles.
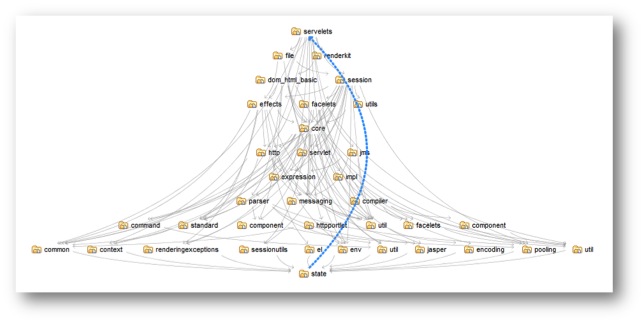
The impact on the system coupling is dramatic – for example where “command” (left of 3rd row up) initially depended on just a few other items in the acyclic system (common and util directly, state indirectly), it now depends (directly or indirectly) on every other item in the system! In fact every item depends on every other, so the CCD has rocketed to over 1,200! In this example we know which is the disruptive dependency because we added it to the clean, acyclic structure and then highlighted it on the resulting diagram. But in reality cyclic dependencies can make a system an order of magnitude harder to understand and maintain, whatever way you measure it.
One Comment
Christian Pfahl
Hi Chris,
great post with an easy explanation of a complex topic!