This guest post was originally published on LinkedIn and is included here with kind permission.
The rise of polyglot programming
The need for software on all sorts of domains (“software is eating the world”) has pushed the need for more developers, fast. As more professionals are hired, better scrutiny is necessary if we are to build malleable software which can evolve and constantly adapt – see “Building Evolutionary Architectures”.
With the current trend of single-page web applications (usually written in Javascript- or Typescript-based frameworks and libraries such as React, AngularJS among others), the concern for software maintenance on the front-end has grown. How can we define a layered and componentized front-end structure and make sure that only code which conforms to this structure is accepted? What kinds of Fitness Functions can be used to perform architecture control on the front-end?
On the back-end the pain is no different. Companies usually have legacy monoliths which they have been trying to strangle into smaller services (or at least into a monolith with a plugin-based architecture). Very often the programming language used for services is different from the original monolith, and the array of languages for the back-end increases inside the company. Python, Java, C#, TypeScript, Go are some of the popular ones. The quest for architectural fitness functions still applies. Can it be done in a uniform way?
A Quick Definition of Architecture
If you still haven’t watched “Real Architecture: Engineering? or Pompous Bullshit?” you should (slides here). It offers a more precise definition and scope of the term “architecture” in the software domain, with some pearls of wisdom such as:
“The architecture is there to satisfy requirements. Architecture that never refers to necessary qualities, performance characteristics, costs, and constraints Is not really architecture. Of any kind.”
Here we will focus on a narrower concept of architecture, as seen in materials from Bob Martin and others (see this blog post and this book, for example). More specifically, we want to focus on a subset of the qualities and constraints – we want to focus on features that facilitate maintenance, sustainability and evolution.
Addressing the Company Culture
At Softplan we have been using a maturity assessment of teams inspired by martial arts and belts. Areas of expertise (Customer Success, User Experience, DevOps Culture, etc) are assessed according to different levels of difficulty and a colored pin is given to that team. As teams move up in their maturity, they are awarded cash for a nice barbecue party for the team, among other things:

One of these areas of expertise which is assessed is architecture skills (aiming at malleability and software maintenance), which we divide into two main kinds:
1) “Micro Architecture”
Here we look into things like Cyclomatic Complexity, number of lines of code in a method/function and other metrics which reflect the tidiness of the code when looked at “up close”. We use a little tool we wrote called srccheck to generate histograms and interactive svg scatter plots which can be used by tech leads to keep an eye on these values.

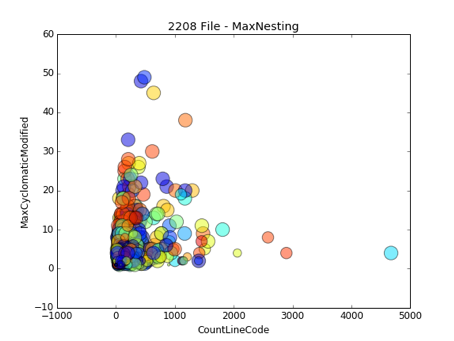
Unlike other tools which only allow a limit on the maximum amount of a metric to fail a build or merge request, we can perform filtering on max, median, standard deviation, average, variance, etc. This allows teams to tolerate exceptional cases of a higher metric value while constraining the remaining elements into smaller values via smaller median and variance. This is particularly useful when strangling legacy or for optimized code with outliers.
Currently srccheck supports most languages which SciTools Understand supports: Java, C#, Delphi, Python, JavaScript/Typescript (“Web” in their tooling), C/C++.
2) “Macro Architecture”
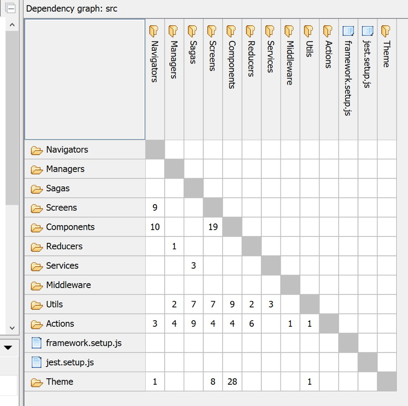
Here we look at how well organized the layers and components are. We look at two main variables – Tangle and Fat, both supported by Structure101 and nicely plotted by their tool:
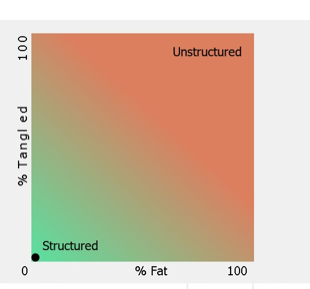
For micro and macro architecture, teams commit to a given maturity level by incorporating metric values for Fat, Tangle, Cyclomatic Complexity etc in their GitLab pipelines. Any merge request is fed through the pipeline, then these fitness functions are executed (Structure101 Build is invoked from the command-line) and code is rejected if it is below the agreed upon maturity level. Here is an example of such a pipeline:
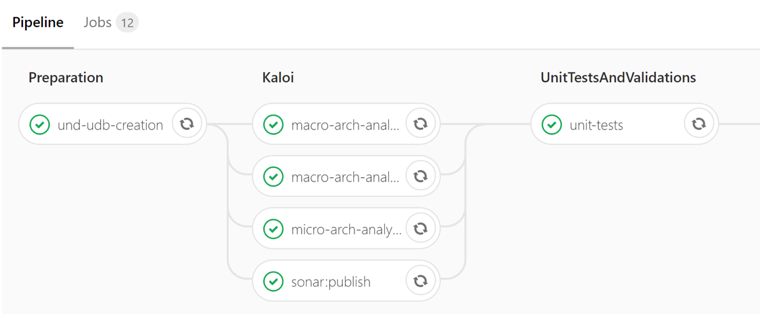
Note how we have Kaloi steps for both micro and macro architecture – after the UDB creation phase.
In order to support microarchitecture control under polyglot programming we wrote a Structure101g “plugin” (flavor) named net.betterdeveloper.understand which takes the SciTools Understand .udb file and outputs an XML for Structure101g (behind the scenes, transparent to the user). Structure101g then does its work and enables architecture control for Python, JavaScript, Typescript, Delphi and C++ just like Structure101‘s native versions for Java and C#.
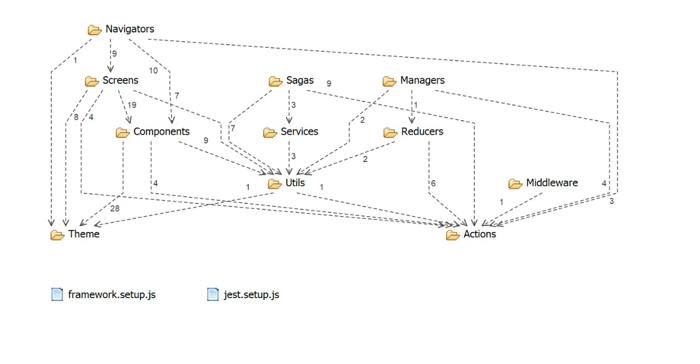
Here is an example – separating reducers from actions in a JavaScript project:
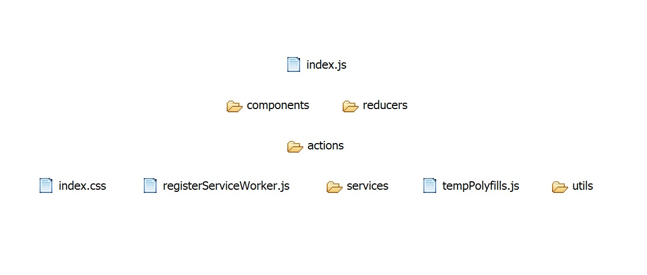
Here we can see the dependencies between reducers and actions:

Lessons Learned
In this process of macro architecture control over the years we have learned a few lessons, some of them specific to each programming language. We’ll share a few.
Python
The community has many different levels of tutorials, some of which induce people into writing tangled code. One such example is the use of an SQLAlchemy plugin for Flask, which will introduce a tangle in your code, making Models depend on Controllers (REST layer) and vice-versa. We have presented this problem at Python Brasil 2016 (the slides in Portuguese are here and the screencast is here). Borrowing some images from that presentation, here is the DSM notation of the dependencies when the Flask-SQLAlchemy plugin is used:

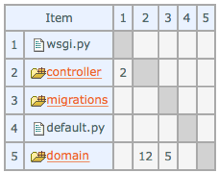
The matrix should be sub-diagonal and it isn’t – indicating a tangle in the code (between controller and domain). Fortunately, a GitLab pipeline was used and the issue was detected:

After fixing the tangle, the correct DSM looks like this (no tangles):
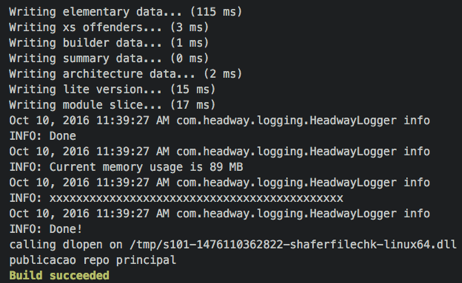
And the pipeline is green:

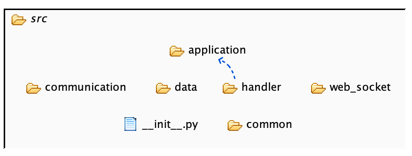
Another issue we see in Python projects is the abuse of __init__.py in a package. It can refer to elements in subpackages, but these subpackages have an implicit import dependency on __init__.py of all parent packages, leading to a circular dependency (tangle) detected by Understand and exposed in Structure101g via our net.betterdeveloper.understand flavor/plugin. This cultural habit was a problem to deal with. For greenfield projects it was not an issue – it can be prevented with Structure101g, rejecting such code. But for Python legacy code, it meant running Structure101g Build in “reject code which increases the number of tangles, but accept existing ones” mode until we could pragmatically get rid of the tangles. You really want to enable Structure101g in your project at day 1 to avoid this kind of pain. Here is an example of tangle detected when the team took too long to instrument the build pipeline with Structure101g at Softplan:


But this sort of problem is not exclusive to Softplan. Here is Django itself:
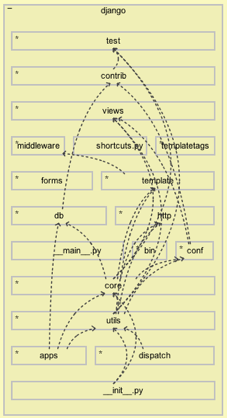
You can see __init__.py tangles, among others.
The lesson here is that as Python becomes more widespread in polyglot setups, architecture control with Structure101g becomes a must-have.
Java and C#
Structure101 Studio for Java and Structure101 Studio for .NET take compiled binaries as input. However, some tools such as Lombok perform some code generation and/or weaving which introduce tangles in the generated code. Fortunately, Structure101 has excellent configurability and these can be excluded. Just keep an eye for them.
Another point that deserves attention is the fact that some Java projects prefer to use com.mycompany.entity.layer (e.g. com.softplan.book.model, com.softplan.book.view, etc) instead of com.mycompany.layer.entity (e.g. com.softplan.model.book, com.softplan.view.book, etc) and this can produce tangles in automatic mode, when you assume that packages represent layering. Fortunately, you can use Model Transformations among other Structure101 features to better model the logical layering of your way of modeling things in code. You may prefer to align your components with the POM files instead of packages – all supported by the tool, fortunately.
Another issue for us was the fact that some Java projects put pure interfaces in a “parent package” and Impl classes in a sub-package (even though, strictly speaking, the package model in Java is not truly hierarchical – unlike C# or Python which are truly hierarchical). This may produce artificial tangles where clients import the interfaces but the dependency sees an import into the concrete implementation, leading to an undesired structure. Separating APIs and IMPLs into “brother packages” achieves true separation and solves this issue – albeit with resistance from some of our Java developers. Model Transformations is another possibility, which can avoid code changes.
JavaScript and Typescript
Convincing pure front-end developers that architecture matters and there are tools for that can be time consuming. It generally isn’t a problem for developers with previous Java background, though. Agreeing on a structure for folders in the project is also time consuming. Due to the fact that the language does not have a native namespace/package mechanism like Java, C# and Python, the folder structure takes that role (the same is done when analyzing C/C++ code in our net.betterdeveloper.understand Structure101g flavor). However, some front-end developers like to structure projects by feature and others by layers or even components. The real challenge is being able to cover all of these – something that can be done with Model Transformations and also multiple architecture rules in Structure101g. In other words, your problems won’t be technical. The real challenge will be changing the culture and achieving consensus among people on the same team and across teams in the same company. For example, below we show two separate architecture rules from two separate teams using React.
Team A organized things like this:

Team B organized things like this:
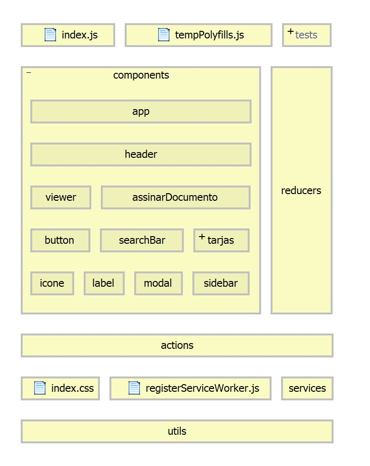
One desired feature of the “Team B” approach above is the use of a Model Transformation to collect all tests into a logical folder/package named “tests” at the top. This is very useful and important both for JavaScript/Typescript as well as Python, where developers often put test code in the same folders as production code, which can cause tangles between production code and tests. By ensuring there is a logical component/folder for tests and putting it above all else in the architecture ensures that no production code uses test code. An alternative to a Model Transformation is the use of a specific architecture rule/diagram for this constraint (“no production code can use test code”).
Our challenge now is to reach consensus and make sure the macro architecture and layers for the different React projects follow the same rationale, with the best insights from the multiple teams.
On the other hand, the good news is that our mobile products are written with React Native, so this sort of architecture control is just as valuable for mobile development:

But note that React Native is yet another case where there is much in common with non-mobile, so some architectural rules and sub-diagrams should be the same. More peopleware work is necessary here to reach consensus.
C and C++
Previously at Audaces (circa 2009) we did a similar effort around its Vestuario CAD and IDEA products, among others. Structure101g with our custom flavor allowed us to refactor the tangled CAD monolith into a plugin-based architecture using SOF. The main challenge was in converting a legacy folder structure that was very tangled (all .h files in a single “includes” directory) into a more componentized structure where each component was in a folder and had its own includes and impl subfolders. After all, traditional C/C++ code does not use namespaces like Java – it uses folders to organize code. The component structure becomes all tangled if not properly designed. Structure101g was used to prevent more tangles from being added, while continuous builds with Jenkins allowed the team to converge to the better architecture designed in the tool.
A major gotcha with C and C++ analysis is due to the fact that elements are declared in one file (.h) and implemented in another file (.c, .cpp) so when a dependency exists, one has to be careful to properly detect if it is a dependency into the .h (better, API) or into the .c file (worse, implementation detail). Mastering this is key for a proper C/C++ redesign into a better architecture with regards to tangle and fat.
Here is an example of Structure101g with our net.betterdeveloper.understand flavor analyzing an Open Source flight simulator in C++ and showing tangles when folders are considered the modules of the system:
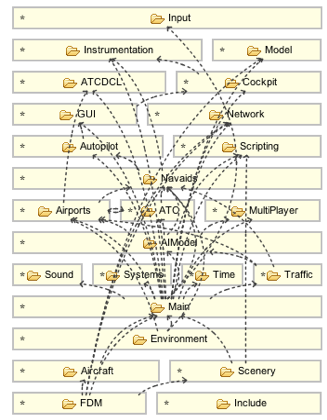
At Softplan we don’t have C++ based products or microservices, though.
Kotlin, Go, Ruby, PHP
The lack of support for Kotlin in both Structure101 and Understand is a limiting factor for Kotlin adoption for us. Analyzing JVM bytecodes can be misleading, much like with Lombok for Java, but at a much higher rate. This is unfortunate, as many of our Java developers see new C# features which they wish they could use on the JVM, and Kotlin would be an easy route for that.
Go is not supported by Understand, but has an experimental Structure101g plugin which seems to be in suspended mode. We haven’t put any effort ourselves into writing a custom Go plugin due to lack of time, unfortunately. However, we do have Go initiatives at Softplan and we are deciding what to do. Ideally, we would like to see Understand support Go as well.
Ruby is not supported by Understand, so the same applies. Fortunately, we have no Ruby projects at Softplan, so we don’t need to deal with this problem.
PHP, on the other hand, is supported by Understand. In theory our net.betterdeveloper.understand flavor could be extended to analyze PHP information as well. However, we have put no effort into this, as we have no PHP back-ends at Softplan.
Delphi
Softplan does have legacy application servers and desktop software written in Delphi (Pascal), which are being decommissioned and replaced by smaller back-end services (REST and GraphQL) using the languages mentioned above, interacting with React-based web fronts. Using Structure101g over the years allowed a better understanding and control of the components to prevent further decay when new team members made mistakes introducing new component circularities – Jenkins builds allowed such anomalies to be detected as soon as they happened.
Like C and C++, traditional Delphi code does not make use of packages/namespaces, relying instead on folders to organize the code. By using a monorepo approach the company unfortunately facilitated the abuse of imports and tangles proliferated before Structure101g was brought into the scene.
The fact that folders have a shallow structure in traditional Delphi projects results in many .pas files in them, which also increases Fat significantly. The traditional approach is to use file prefixes (uaipFoo.pas, uedtBar.pas) so we are evaluating switching to Model Transformations based on these prefixes to better organize the files/units into logical nested packages. Currently XS is high because of tangles and because of these folders with too many .pas files (flat).
Future Work
We will be comparing a layered-based approach versus feature-based approach and component-based approach for front-ends (for a detailed discussion of the topic, see chapter 34 of this book). Hopefully we will turn that into a new article in the near future.
On the Python front, we have implemented a flavor which does not need SciTools Understand to perform its analysis (with the drawback of only capturing dependencies at the file import level). It is quite useful and has been used by close friends with success. If you are interested, drop us a message.
About the Author
Marcio Marchini is Chief Architect at Softplan, where he oversees the architectural decisions across products and leads the Enterprise Architecture team, responsible for designing the fitness functions for architecture governance. He has also been working as a consultant over the years helping companies tame their legacy code and prevent their greenfield microservices from becoming mini monoliths quickly. You can reach out to Marcio on LinkedIn .
3 Comments
Unified APIs and Federated Gateways – Part 1: Unified API, Monolith and Microservices Architecture – For the love of challenges :)
[…] View at Medium.com https://medium.com/@skpallewatta92/microservices-with-netflix-oss-spring-boot-and-non-jvm-applications-2d762768921a View at Medium.com https://structure101.com/2020/02/05/polyglot-architecture-control-and-its-gotchas/ […]
Unified APIs and Federated Gateways – Part 2: API Management, Service Mesh, DAPR – For the love of challenges :)
[…] View at Medium.com https://medium.com/@skpallewatta92/microservices-with-netflix-oss-spring-boot-and-non-jvm-applications-2d762768921a View at Medium.com https://structure101.com/2020/02/05/polyglot-architecture-control-and-its-gotchas/ […]
Unified APIs and Federated Gateways – Part 3: GraphQL, GraphQL Mesh, Federated Gateways – For the love of challenges :)
[…] View at Medium.com https://medium.com/@skpallewatta92/microservices-with-netflix-oss-spring-boot-and-non-jvm-applications-2d762768921a View at Medium.com https://structure101.com/2020/02/05/polyglot-architecture-control-and-its-gotchas/ […]