My recent post on architectural erosion in the findbugs code-base was generally well received, but there were some skeptical voices.
In a comment, Emeric questioned whether cyclic dependencies at the package level are anything more than a smell (if that). Itay Maman was a little more forthright, offering a little series of posts arguing that I was peddling myths, tangled packages are the norm (so they must be okay), and all static analysis is in any case completely pointless.
In both cases, they honed in exclusively on the rather narrow issue of package tangles, while also ignoring the time dimension, and in this sense I think both rather missed the point (though perhaps some more than others).
As I said in the opening paragraph of the original post, the key for me is levels of abstraction above the raw code: architectural components within a code-base if you like. In the case of findbugs, there are several instances where you can see that an architectural decision was made, only for this to be come blurred and ultimately lost over time. In all the early releases (e.g. 0.8.6), and surely not by accident, the ba component does not use the findbugs component. In 0.8.8, a rogue dependency creeps in. If you follow the full series of snapshots, you will see that this back dependency steadily rises from an initial weight of 2 code-level references (that could be easily reversed out) to the point where the interdependency is deeply entrenched in the code. Other examples are the blurring of the relationship between config and findbugs, and the attempt to interface off the dependencies on the specific parser library (asm or bcel).
{kind=link}
{kind=link}
{kind=link}
It is not in the least bit surprising to me that this form of erosion happens over time for the simple reason that it is generally invisible. How can we rationalize about that which we cannot see (or measure, or define)?
Enter Structure101. This is based on the simple principle that, in order for design items to be first class citizens in the code-base, we need to be able to see them and, especially, the interactions between them.
Note that I am using terms like “architectural component” and “design item”, not “package”. In general, I am loathe to assume that there is necessarily a one-to-one correspondence between the Java package hierarchy on the one hand, and the “design hierarchy” on the other – for sure, there is absolutely nothing in the language specification to say that this must be so. I can say with confidence that this correlation exists for the Structure101 code-base (because I co-own it) and the Spring code-base (because they make a lot of noise about it), but I think this is a dubious assumption in general. For findbugs, however, I think this little leap-of-faith was reasonable given the clarity of the package diagrams in the early releases.
Now suppose that you have do have a code-base with a formal design hierarchy but one that does not correspond to the package structure. If you point Structure101 at that code-base, the initial (default) views will leave you completely cold because you are looking at the interactions between arbitrary subsets of code. You don’t care about these in the slightest, and quite rightly so. However, that does not mean that the tool is of no use – you can use transformations to map the code so that the resulting hierarchy does mirror the design. This scenario is actually quite common, for instance where the first level of breakout is managed via separate IDE projects / jar files and the logical package view results in (unintended) package name collisions.
With that background in place, let’s take a closer look at some of the dissenting voices.
@Emeric
But what are your arguments to say that 2 or 3 interdependents packages are a “blob” which you imply is bad ?
Don’t these packages deserve a name in their own and an isolation of comprehension even if they have cyclic dependencies ?
I think they initially deserve the separation, even with cyclic dependencies.
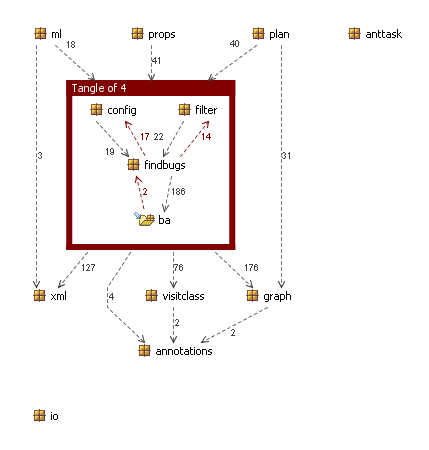
This does not seem unreasonable and is in fact a good fit with the tangle of findbugs, config and filter in 0.8.8. Here is the raw package diagram (note that I’m excluding io and anttask as noise):

So let’s transform this model to introduce a new architectural component – controller – as the union of all three of these. Here’s what we get:

This gives us a much better view of the architectural components at this level in the code-base, and shows just the one (clearly) rogue dependency from ba back to the controller. Needless to say, if we drill into the controller component, we will see that it contains package tangles…

… but it is essentially up to you (the user, team, …) whether or not you choose to care about this. Indeed, you can formally capture those things you do care about (and, by implication, those you do not) using architecture diagrams. Note however that the XS (excessive complexity) metric will always punish tangles at higher levels in the code (in that it measures distance from a structural ideal) – more on this in a bit.
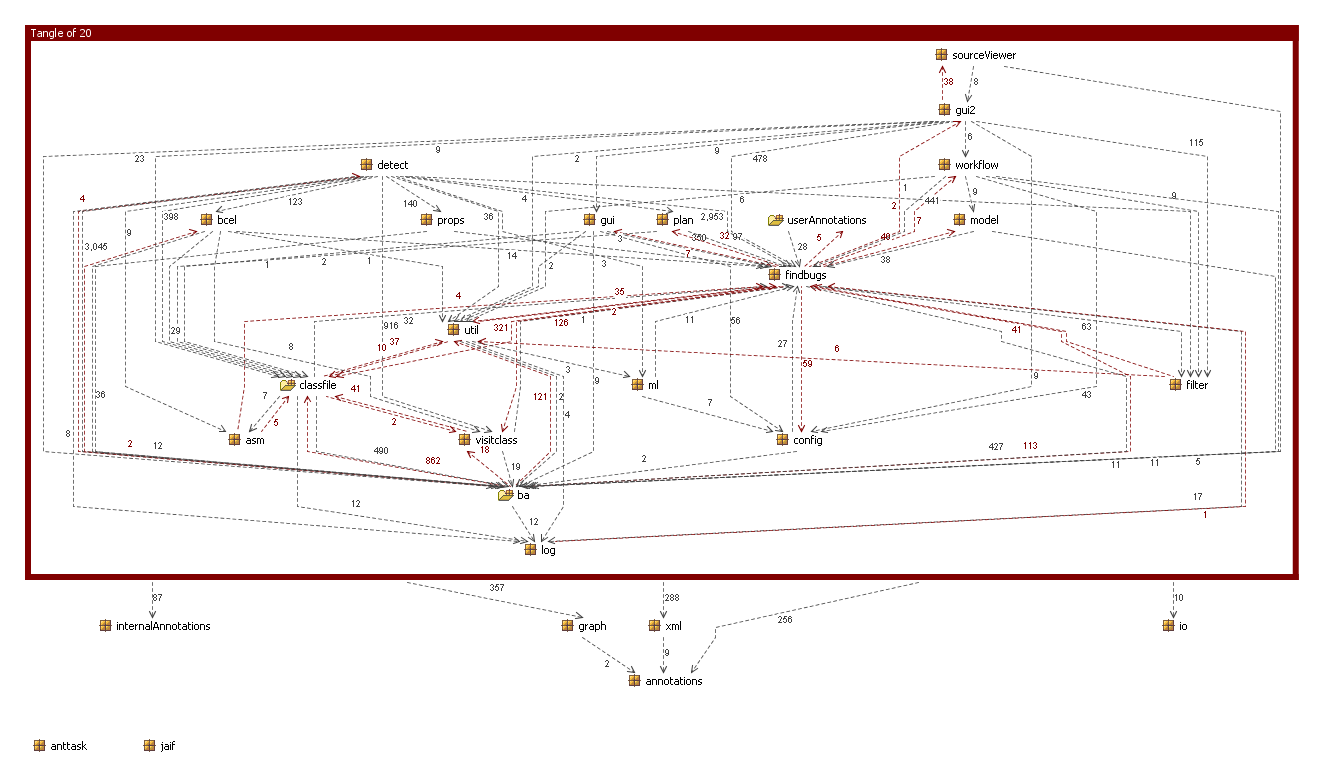
Let’s now take another look at the most recent version (1.3.5). We could apply the same principle here, and transform all the packages involved in the tangle into a single “architectural component”, though this time it’s harder to think of a name. Let’s go with … errr … blob.
{kind=link}

And, hey presto, we have an acyclic graph at the first level of breakout. However, 99% of the code-base is now located within blob so we have not really achieved terribly much in terms of architectural divide & conquer. Also, needless to say, the package breakout within the blob component is still essentially anarchic.

This leads on to the final point about package tangles. There is always a simple fix way to fix any package tangle: just merge all the classes into a single package. Here is another view of the blob component (ok, so you’ll need very good eyesight for this one) but this time I tweaked the transformations to strip out all the sub-packaging.

This one is way too “fat” (642 classes and 6,830 dependencies) to do as a nice diagram so I switched to a matrix view and set the cell size to 1 pixel. In many ways, I prefer this view because it is a much more accurate representation of how the code really is (a bunch of classes), as opposed to the raw package view which is basically just showing arbitrary subsets. That said, this view doesn’t actually help me to understand the code-base in any way shape, or form. Instead, it makes me think of Jonathan Edwards’ fine quote that “the human mind can not grasp the complexity of a moderately sized program, much less the monster systems we build today“.
This aspect of structure – the dichotomy between tangles and fat – is important when it comes to measurement, since it is clearly insufficient to take account of one without the other. The XS metric does factor in both sides of this coin – I do not claim that it is perfect, but I do rather suspect it is the best we have.
@Emeric
I agree that cyclic dependencies is a bad smell, except perhaps when there is a large dependency [in one direction] and a small backward dependency [in the other].
I agree that cyclic dependencies between packages is merely a smell, but I would argue that cyclic dependencies between architectural components is more than that. Where the backward dependency is small, I would see this as probably indicating good abstractions but with some rogue code that should ideally be fixed some time (but see also Keep A Lid On It). Heavy interdependency between architectural components is essentially the same state as no architectural components…
@Emeric
May I ask you opinion on the possibility to refactor, in the future, findbugs with Java Modules and friends packages.
I think I have addressed this already in the sense that the design (module, component, …) hierarchy is not necessarily the same as the package hierarchy (friends or no friends) but please follow up if I’m missing something here.
In his “Mythbusting” series, Itay hauls out the scattergun and sprays it around pretty indiscriminately. I was concerned that it would take me a long time to respond to all the various points, but actually I am delighted to says that others have already done a far better job than ever I could have done, so for the most part I will just refer you to the meaty comments sections. However, there is one aspect I would like to follow up on.
Here is the very first line in the very first post:
@Itay
(Disclaimer: as always, the issue of reasoning about software quality is largely a matter of personal judgment)
This is later fleshed out a little more (in a comment):
@Itay
It all boils down to the fact that we don’t have a single-, absolute-, objective-, metric of software quality (we all wish we had). Hence, we are constantly looking for approximation techniques. We must be careful not to mistake the approximation for the real thing.
This standpoint is thoroughly defensible, and reminds me of a number of conversations I have had with customers about the Structure101 metrics. The general feeling here, however, has consistently been that metrics are critical in terms of bridging the gap between technical staff (who instinctively understand why a particular activity is needed) and management staff (who need things like line charts and red and blue bars to be able to justify such activities further up the food chain). The two most interesting metrics here are XS (mentioned above) and number-of-architectural-violations. The former is all predefined and set in stone (though you can tweak the thresholds) while the latter is totally in the control of the team because it is calculated based on the architecture diagrams that the team (not the tool) defines. Some customers use one, some the other, and some both. I think it is correct to say that all are careful and none would claim for a second that these are absolute measures of perfection.
Had this – being careful with stats and metrics – been the essence of Itay’s posts, I think he would have caused less of a storm (though perhaps the storm was always his objective). Instead, Itay chose to mostly bury the “being careful…” bit and lead with sweeping statements such as “Dependency analysis is largely useless”. Shame…
4 Comments
Patrick Smacchia
Same problematic in the .NET world:
http://www.theserverside.net/tt/articles/showarticle.tss?id=ControllingDependencies
Itay Maman
Hi Ian,
Thanks for making this post. Although I don’t agree with some of the points, they are very well argued.
I didn’t mean to bash neither you nor S101. If it came out that way it was unintentional and I apologize for that. My problem is with the static analysis approach as a whole. I am not saying that the approach is always wrong. However, it is definitely sometimes wrong (see formal proof in link-1, below).
I think the software development community does not yet know where exactly the boundaries of the approach lie. I am trying to help us draw these boundaries by highlighting examples where the approach does not work.
Anyway, in order to keep this debate manageable, I will only put my main comments here, starting from the most important one.
“in order for design items to be first class citizens in the code-base, we need to be able to see them and, especially, the interactions between them.”
First, some programs enjoyed great benefits from design items that are not first class citizens in the code-base. Any external DSL (and to some extent, internal DSL) is not a first class citizen of the code base. Other examples: the property pattern, adaptive object models, table-driven programming.
Second, the introduction of interfaces to solve dependency issues makes it more difficult to see the static interaction between the collaborating classes. The statement in this quote is quite similar to the one made by Fowler’s “To Be Explicit” article (see link-2). One of the examples there argues that the observer pattern makes relationship less explicit which is bad. However, this is at odds with the “tangles are bad” approach. Again, a small conundrum.
I am not saying programmers cannot solve this conundrum by relying on their wits, experience and skills. I am just saying that indiscriminate application of what I call “formulas” is likely to get them into troubles.
“As I said in the opening paragraph of the original post, the key for me is levels of abstraction above the raw code: architectural components within a code-base if you like.”
Abstraction means losing (inessential) details. Could you rationalize why the details that are *not* shown by S101’s views (in particular, runtime behavior) have a lesser impact on quality than the details that *are* shown? I assume this would be hard due to (again) the lack of this “magic-quality-metric”
“In the case of findbugs, there are several instances where you can see that an architectural decision was made, only for this to become blurred and ultimately lost over time.”
How do you know that the lost of the initial intention was not deliberate nor fruitful?
“but it is essentially up to you (the user, team, …) whether or not you choose to care about this”
I couldn’t agree more. The information exposed by static analysis needs to pass through a project-specific-filter. Without an “external intervention” it could be interpreted in many different, probably wrong, ways.
Link-1: http://javadots.blogspot.com/2008/12/formalizing-paradox.html
Link-2: http://martinfowler.com/ieeeSoftware/explicit.pdf
Itay Maman
Hi Ian, One more thought.
Suppose you rewrite a program with tangles using a language that is similar to Java but supports structural subtyping. With such a language eradication of tangles is really easy.
So, the new version of the program will have no tangles. Using tangle-count as a quality indicator, we improved the design by an infinite factor (from some n to zero).
Do you really think that the architecture of the new version of the program will never-erode? Do you think it will be much easier to maintain it?
Ian Sutton
@Itay Maman
I do appreciate your more measured tone here 😉
I just added a new post which has some overlaps with this one, hence this retrospective comment/response.
-Ian